Description:
Explore real-world production incident stories from managing hundreds of Kubernetes clusters, with a focus on clusters scaling to 10K+ nodes. Learn how seemingly simple operations like adding a single node or modifying a configmap can trigger chain reactions that disrupt entire clusters. Discover best practices for maintaining high cluster availability through lessons learned from failures involving postmodern databases, automation, user escalation, and paradoxical finalizers. Gain insights into mitigating paging storms, handling manual operations, and improving monitoring dashboards. Understand the importance of security context changes and key takeaways for effectively managing large-scale Kubernetes environments.
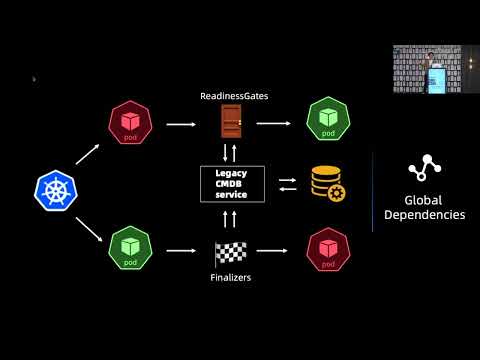
How to Not Destroy Your Production Kubernetes Clusters
Add to list
#Conference Talks
#SREcon
#Computer Science
#DevOps
#Kubernetes
#Information Security (InfoSec)
#Cybersecurity
#Security Management
#Information Technology
#Incident Management
0:00 / 0:00