Description:
Explore a 15-minute conference talk from USENIX ATC '21 that introduces data refurbishing, a novel sample reuse mechanism to accelerate deep neural network training while preserving model generalization. Learn how this technique splits data augmentation into partial and final stages, reusing partially augmented samples to reduce CPU computation while maintaining sample diversity. Discover the design and implementation of Revamper, a new data loading system that maximizes overlap between CPU and deep learning accelerators. Examine the evaluation results showing how Revamper can accelerate training of computer vision models by 1.03×–2.04× while maintaining comparable accuracy. Gain insights into the DNN training pipeline, challenges of data augmentation, and innovative solutions for improving training efficiency.
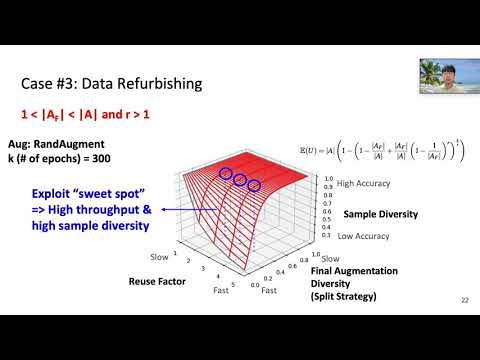
Refurbish Your Training Data - Reusing Partially Augmented Samples for Faster Deep Neural Network Training
Add to list
#Conference Talks
#USENIX Annual Technical Conference
#Computer Science
#Deep Learning
#PyTorch
#Machine Learning
#Data Augmentation