Description:
Explore a comprehensive video explanation of the machine learning research paper "TransGAN: Two Transformers Can Make One Strong GAN." Delve into the groundbreaking approach of using transformer-based architectures for both the generator and discriminator in Generative Adversarial Networks (GANs). Learn about the innovative techniques employed, including data augmentation with DiffAug, super-resolution co-training, and localized initialization of self-attention. Discover how TransGAN achieves competitive performance with convolutional GANs on various datasets and gain insights into the future potential of transformer-based GANs in computer vision tasks.
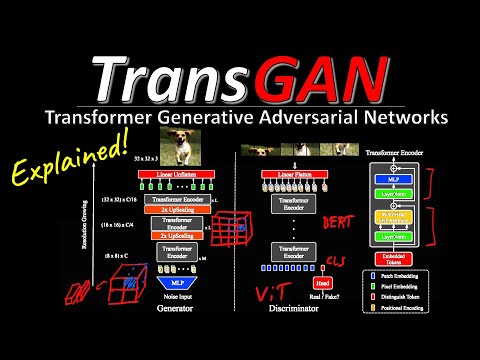
TransGAN - Two Transformers Can Make One Strong GAN - Machine Learning Research Paper Explained
Add to list
#Computer Science
#Artificial Intelligence
#Neural Networks
#Generative Adversarial Networks (GAN)
#Machine Learning
#Computer Vision
#Data Augmentation
#Deep Learning
#Transformer Architecture
#Self-Attention