Description:
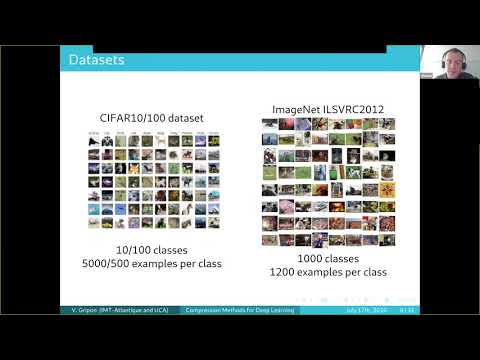
Explore a comprehensive review of compression methods for deep convolutional neural networks in this 58-minute tinyML Talks webcast. Delve into Professor Vincent Gripon's expertise as he discusses various techniques to compress and accelerate CNNs, including pruning, distillation, clustering, and quantization. Gain insights into the pros and cons of each method, understanding how to reduce the size of CNN architectures for tinyML devices without compromising accuracy. Learn about deep learning challenges, data centers, layers, datasets, architectures, and the number of operations in convolutional layers. Examine quantization experiments, flops rates, and energy consumption. Participate in a Q&A session to further explore the topic and clarify any questions about deploying CNNs on resource-constrained devices.
A Review of Compression Methods for Deep Convolutional Neural Networks
Add to list
#Computer Science
#Artificial Intelligence
#Neural Networks
#Neural Network Architecture
#Machine Learning
#Quantization
#Clustering
#Distillation