Description:
Explore optimization algorithms for compressing neural networks in this tinyML Talks webcast. Dive into the challenges of deploying advanced networks on resource-constrained systems and learn about various compression techniques. Discover the functionality of common compression algorithms, including pruning, quantization, and knowledge distillation. Examine the pros and cons of different pruning techniques, and explore concepts such as lowend factorization, fast convolutional networks, and selective attention networks. Gain insights into general use cases and the process of pruning whole channels. This comprehensive talk, presented by Marcus Rüb from the Hahn-Schickard Research Institute, provides a valuable introduction to making neural networks more efficient for embedded devices and mobile applications.
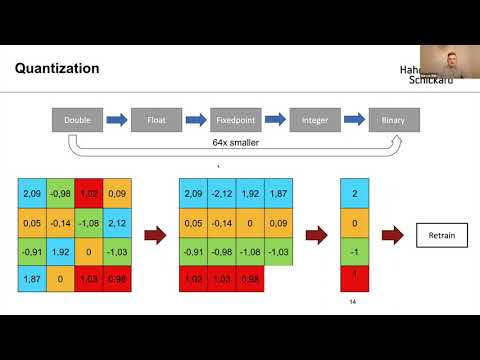
Introduction to Optimization Algorithms to Compress Neural Networks
Add to list
#Computer Science
#Deep Learning
#Engineering
#Electrical Engineering
#Embedded Systems
#Machine Learning
#Quantization
#Algorithms
#Optimization Algorithms