Description:
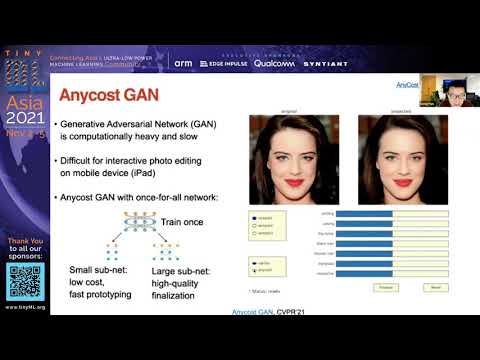
Explore cutting-edge techniques for efficient deep learning and TinyML in this plenary talk from tinyML Asia 2021. Discover how to put AI on a diet as MIT EECS Assistant Professor Song Han presents innovative approaches to model compression, neural architecture search, and new design primitives. Learn about MCUNet, which enables ImageNet-scale inference on micro-controllers with only 1MB of Flash, and the Once-for-All Network, an elastic neural architecture search method adaptable to various hardware constraints. Gain insights into advanced primitives for video understanding and point cloud recognition, including award-winning solutions from low-power computer vision challenges. Understand how these TinyML techniques can make AI greener, faster, and more accessible, addressing the global silicon shortage and enabling practical deployment of AI applications across various domains.
Putting AI on a Diet: TinyML and Efficient Deep Learning
Add to list
#Computer Science
#Machine Learning
#TinyML
#Artificial Intelligence
#Computer Vision
#Neural Architecture Search
#Model Compression