Description:
Dive deep into the Transformer Neural Network Architecture for language translation in this comprehensive 28-minute video. Explore key concepts including batch data processing, fixed-length sequences, embeddings, positional encodings, query/key/value vectors, masked multi-head self-attention, residual connections, layer normalization, decoder architecture, cross-attention mechanisms, tokenization, and word generation. Gain practical insights through a Transformer inference example and access additional resources for further learning on neural networks, machine learning, and related mathematical concepts.
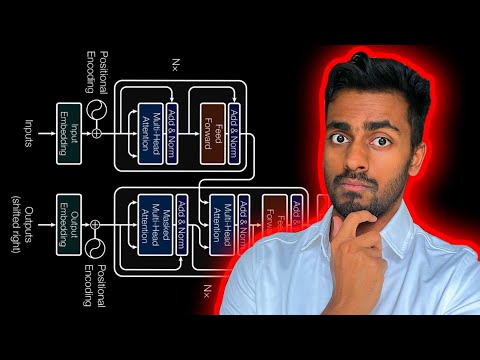
The Complete Guide to Transformer Neural Networks
Add to list
#Computer Science
#Artificial Intelligence
#Neural Networks
#Machine Learning
#Embeddings
#Deep Learning
#Positional Encoding