Description:
Explore the innovative StreamingLLM technique for deploying language models in streaming applications with long text sequences and limited memory. Discover the "attention sink" phenomenon and learn how it can be leveraged to process infinite text lengths without fine-tuning. Understand the challenges of existing window-based KV cache methods and the suboptimal eviction policies they employ. Gain insights into a novel approach that maintains attention sinks in the KV cache while utilizing a sliding window mechanism for the remaining tokens. Access the implementation code on GitHub to further investigate this cutting-edge solution for efficient language model deployment.
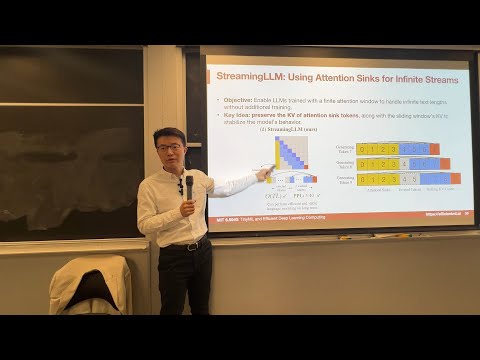
StreamingLLM: Deploying Language Models for Streaming Applications with Long Text Sequences
Add to list