Description:
Explore the inner workings of Datadog's metrics backend in this SREcon22 Americas conference talk. Delve into the evolution of Datadog's distributed system, from its small beginnings to its current large-scale operation across major cloud providers. Learn about the scaling and reliability challenges faced by the team, their solutions, and the key lessons and strategies that emerged. Gain insights into Kafka's role at Datadog, partitioning techniques, and handling various failure scenarios. Discover how the system manages node, availability zone, Kubernetes cluster, and cloud vendor failures. Understand the importance of balanced topics, consumer shards, and addressing partition imbalance. Get a glimpse of unsolved problems and future plans for Datadog's metrics backend. Presented by Adam Mckaig, Staff Engineer, and Tahia Khan, SRE at Datadog, this talk offers valuable knowledge for those interested in large-scale distributed systems and cloud monitoring.
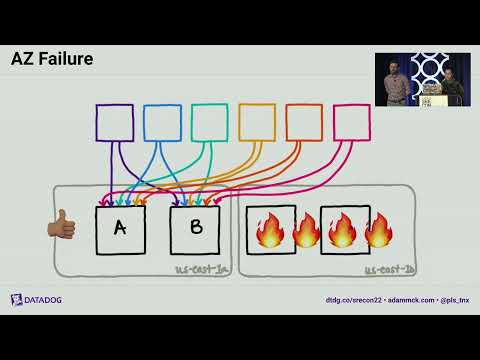
How the Metrics Backend Works at Datadog
Add to list
#Conference Talks
#SREcon
#Computer Science
#Distributed Systems
#Engineering
#Reliability Engineering
#Software Engineering
#Scalability
#Programming
#Cloud Computing
#Cloud Monitoring