Description:
Save Big on Coursera Plus. 7,000+ courses at $160 off. Limited Time Only!
Grab it
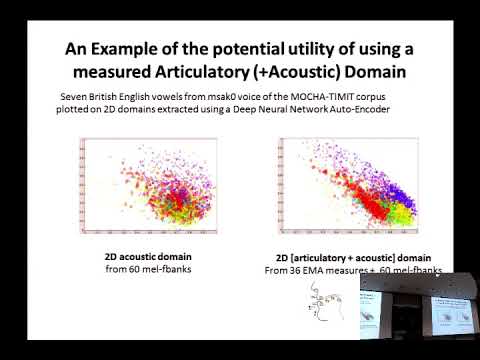
Explore deep neural network acoustic modeling techniques incorporating speech production knowledge in this 55-minute lecture by Leonardo Badino from the Center for Language & Speech Processing at Johns Hopkins University. Delve into two approaches: using vocal tract movement measurements to extract new acoustic features, and deriving continuous-valued speech production knowledge features from binary phonological features to build structured DNN outputs. Examine the results of these methods tested on mngu0 and TIMIT datasets, showing consistent phone recognition error reduction. Learn about the speaker's background in speech technology and current research focus on speech production knowledge for automatic speech recognition, limited resources ASR, and computational analysis of non-verbal sensorimotor communication.
Speech Production Features for Deep Neural Network Acoustic Modeling - 2015
Add to list
#Computer Science
#Deep Learning
#Deep Neural Networks
#Humanities
#Linguistics
#Phonology
#Autoencoders