Description:
Explore a cutting-edge distributed system for training Graph Neural Networks (GNNs) in this 15-minute conference talk from OSDI '21. Learn about Dorylus, an innovative approach that leverages serverless computing to overcome the challenges of expensive GPU servers and limited memory when working with billion-edge graphs. Discover how computation separation enables a deep, bounded-asynchronous pipeline that effectively hides network latency. Understand why CPU servers offer the best performance-per-dollar for large graphs and how integrating Lambda threads can significantly boost efficiency. Gain insights into Dorylus' architecture, its ability to scale GNN training, and its impressive performance compared to existing systems. Delve into the challenges of using serverless computing and the solutions implemented to address limited resources and network constraints.
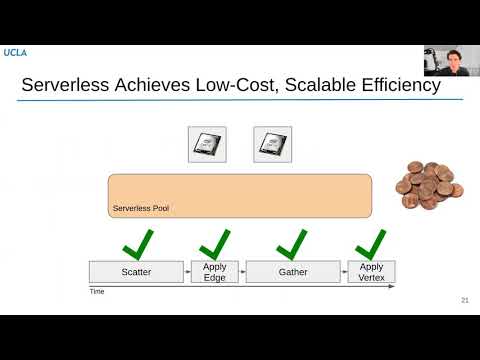
Dorylus - Affordable, Scalable, and Accurate GNN Training with Distributed CPU Servers and Serverless Threads
Add to list
#Conference Talks
#OSDI (Operating Systems Design and Implementation)
#Computer Science
#Deep Learning
#Software Engineering
#Scalability
#Distributed Computing
#Programming
#Cloud Computing
#Serverless Computing