Description:
Explore a 20-minute conference talk by Hoang Tran, Machine Learning Engineer at Snorkel AI, on improving language model performance through human preference modeling. Learn about the development of reward models trained to mimic human annotator preferences and their application in accepting or rejecting base model responses. Discover how this approach significantly enhances model performance with minimal end-user guidance compared to traditional feedback methods. Gain insights into aligning language models with human preferences, direct preference optimization, and programmatic scaling of human preferences. Access accompanying slides, a summary of Snorkel AI's Enterprise LLM Summit, and related video recordings to deepen your understanding of this innovative approach in machine learning and generative AI.
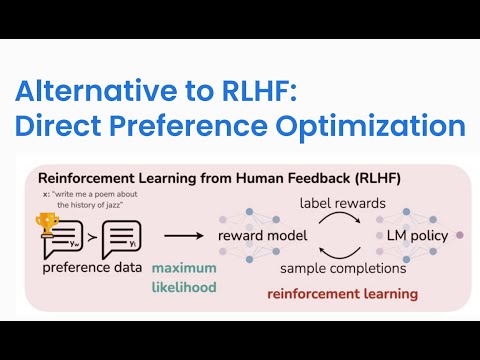
Modeling Human Preference to Improve LLM Performance
Add to list