Description:
Save Big on Coursera Plus. 7,000+ courses at $160 off. Limited Time Only!
Grab it
Aprende a personalizar un Vision Transformer utilizando tu propio conjunto de datos en este tutorial de 58 minutos. Explora cómo usar un modelo base pre-entrenado por Google y entrenar un clasificador con datos propios. Utiliza un subconjunto del conjunto de datos EyePacs llamado EyeQ para crear un modelo que analiza la calidad de imágenes. Accede a los cuadernos de Jupyter en GitHub para seguir el proceso paso a paso y desarrollar habilidades prácticas en aprendizaje automático y visión por computadora.
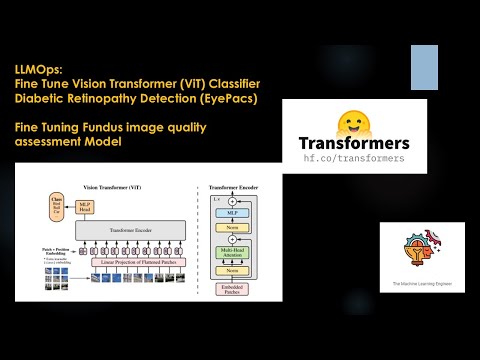
Fine-Tuning ViT Classifier for EyePacs Dataset Quality Model - Tutorial en Español
Add to list
#Computer Science
#Artificial Intelligence
#Computer Vision
#Vision Transformers
#Machine Learning
#Transfer Learning
#Health & Medicine
#Health Care
#Radiology
#Medical Imaging
#Fine-Tuning