Description:
Discover how Zillow empowers its developers with self-service ETL solutions in this 24-minute talk by Databricks. Learn about the creation of multiple self-service platforms designed to meet the growing demand for new data pipelines within the organization. Explore how Zillow's data engineering team addressed the specific needs of data analysts and data producers through two distinct user interfaces. Gain insights into the abstraction levels chosen for each user group, covering orchestration, deployment, and Apache Spark processing implementation. Understand how Zillow leveraged internal services and packages, including their Apache Spark package Pipeler, to democratize the creation of high-quality, reliable pipelines. Delve into the modular design of these platforms and how they empower users to create their own ETL without worrying about implementation details. Examine the process of transformation, user interaction, interpretation, pipeline metadata, rendering layer, and orchestration execution layer in Zillow's ETL system. Gain valuable knowledge about job creation, Zillow's structure, and development process in this informative presentation on self-service ETL solutions.
Read more
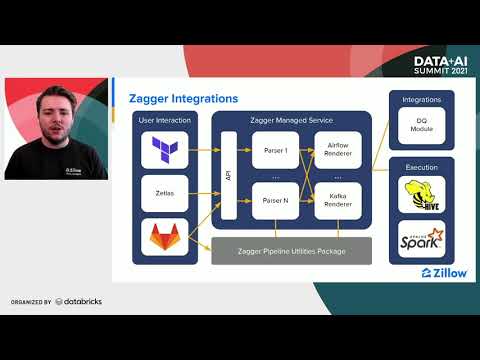
Empowering Developers with Self-Service ETL - Zillow's Approach
Add to list
#Data Science
#Data Engineering
#Big Data
#Apache Spark
#Data Processing
#Data Transformation
#Data Pipelines
#ETL