Description:
Dive into the implementation of a multilayer perceptron (MLP) character-level language model in this comprehensive video tutorial. Learn essential machine learning concepts including model training, learning rate tuning, hyperparameters, evaluation, train/dev/test splits, and under/overfitting. Follow along as the instructor builds a training dataset, implements embedding lookup tables and hidden layers, and explores the internals of PyTorch tensors. Discover how to implement output layers, negative log likelihood loss, and F.cross_entropy. Practice overfitting on a single batch before training on the full dataset with minibatches. Explore techniques for finding optimal learning rates and splitting datasets. Experiment with larger hidden layers and embedding sizes, visualize character embeddings, and learn to sample from the trained model. Access provided resources, including GitHub repositories, Jupyter notebooks, and relevant research papers to enhance your understanding and complete suggested exercises.
Read more
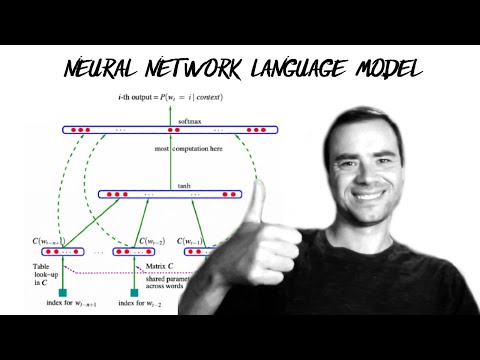
Building Makemore - MLP
Add to list
#Computer Science
#Artificial Intelligence
#Natural Language Processing (NLP)
#Machine Learning
#Deep Learning
#PyTorch
#Overfitting
#Model Training
#Hyperparameters
#Neural Networks
#Multilayer Perceptron