Description:
Discover how to build a knowledge graph using Spark and NLP to recommend novel drugs to scientists. Learn about AstraZeneca's "5R" framework and its impact on improving efficiency in drug discovery. Explore the challenges of parsing large amounts of information from various formats and data models, and how to formulate drug target finding as a hybrid recommendation problem. Delve into the process of assembling a large-scale knowledge graph from public and internal data, focusing on NLP techniques to extract precise information at scale. Gain insights into graph embedding pipelines, approximate nearest neighbor search, and valuable lessons learned in the field of drug discovery and recommendation systems.
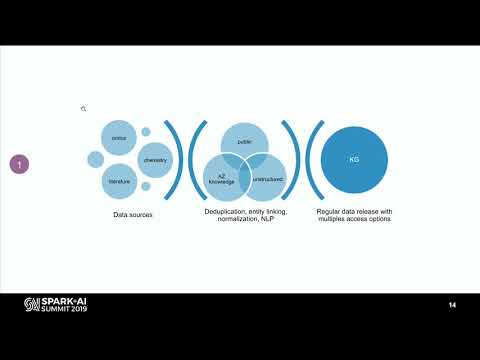
Building a Knowledge Graph with Spark and NLP for Novel Drug Recommendations
Add to list
#Computer Science
#Artificial Intelligence
#Knowledge Graphs
#Data Science
#Bioinformatics
#Machine Learning
#Big Data
#Apache Spark
#Science
#Life Science
#Drug Discovery
#Recommendation Systems
#Mathematics
#Graph Theory
#Graph Embeddings