Description:
Explore machine learning feature engineering techniques for text data using tidymodels in this 34-minute screencast. Learn how to build a support vector machine model to classify Netflix titles as TV shows or movies. Follow along as Julia Silge demonstrates data exploration, feature engineering, model calibration, and evaluation using #TidyTuesday Netflix data. Discover how to create and interpret visualizations like confusion matrices, ROC curves, and variable importance plots. Gain insights into working with text features, handling data budgets, and achieving consistent results in machine learning workflows.
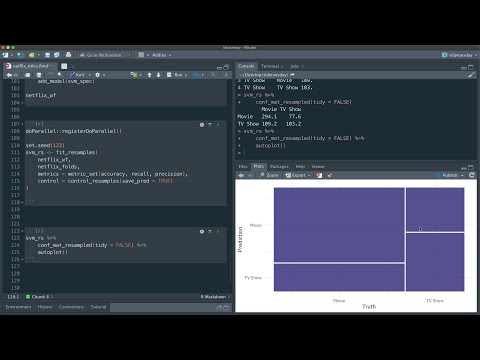
Build Features for Machine Learning from Netflix Description Text
Add to list
#Computer Science
#Machine Learning
#Text Analysis
#Data Science
#Data Analysis
#Data Exploration
#Feature Engineering