Description:
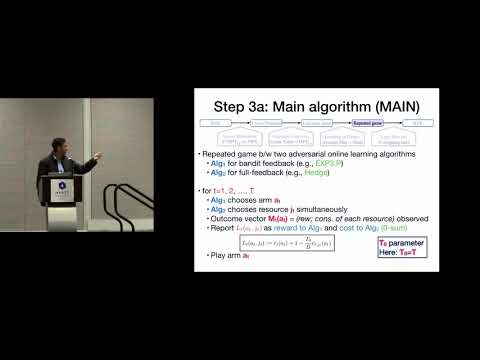
Explore the concept of Adversarial Bandits with Knapsacks in this 21-minute IEEE conference talk. Delve into dynamic pricing, prior work on Stochastic BwK, and various feedback models. Examine the main results, challenges, and reasons behind the complexity of BwK and Adversarial BwK. Learn about linear relaxation, Lagrange games, and the main algorithm (MAIN). Discover regret bounds, simple algorithms, and the differences between high-probability and adaptive adversary scenarios. Conclude with extensions and potential future work in this field.
Adversarial Bandits with Knapsacks
Add to list
#Conference Talks
#IEEE FOCS: Foundations of Computer Science
#Computer Science
#Machine Learning
#Reinforcement Learning
#Algorithm Design
#Mathematics
#Optimization Problems