Description:
Delve into the second part of a comprehensive tutorial on gradient-based optimization methods for large-scale machine learning problems. Explore gradient descent, stochastic gradient descent, and their accelerated versions as presented by Adam Oberman from McGill University. Gain insights into the fundamental concepts behind these algorithms, their convergence results, and their connections to ordinary differential equations. Learn how these first-order methods are essential for tackling high-dimensional optimization challenges where second-order approximations are impractical. This tutorial, part of the High Dimensional Hamilton-Jacobi PDEs Tutorials 2020 series, offers valuable knowledge for researchers and practitioners working on advanced machine learning optimization techniques.
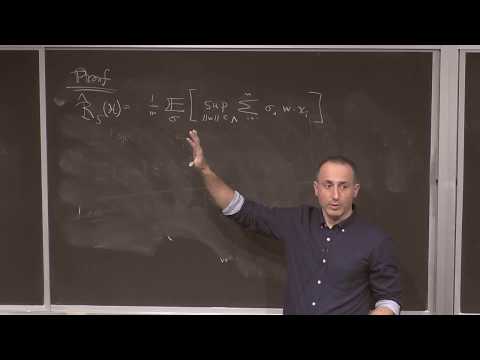
Gradient Descent, Stochastic Gradient Descent, and Acceleration - Part 2
Add to list
#Computer Science
#Machine Learning
#Gradient Descent
#Mathematics
#Differential Equations
#Ordinary Differential Equations
#Computational Mathematics
#Stochastic Gradient Descent