Description:
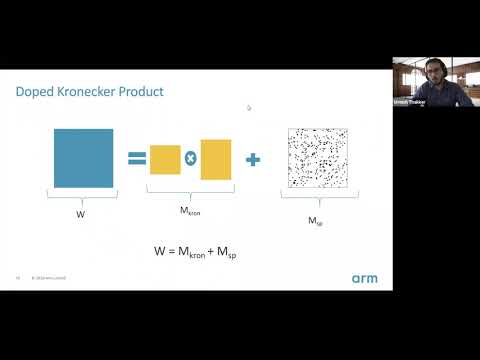
Explore a technique for extreme compression of LSTM models using sparse structured additive matrices in this tinyML Talks webcast. Learn about structured matrices derived from Kronecker products and their effectiveness in compressing neural networks. Discover the concept of "doping" - adding an extremely sparse matrix to a structured matrix - and how it provides additional degrees of freedom for parameters. Understand the challenges of training LSTMs with doped structured matrices, including co-matrix adaptation and the need for co-matrix dropout regularization. Examine empirical evidence demonstrating the applicability of these concepts to multiple structured matrices. Delve into state-of-the-art accuracy results at large compression factors across natural language processing applications. Compare the doped Kronecker product compression technique to previous compression methods, pruning, and low-rank alternatives. Investigate the deployment of doped KP on commodity hardware and the resulting inference run-time speed-ups. Cover topics such as training curves, output feature vectors, regularization techniques, controlling sparsity, and limitations of the approach.
Read more
A Technique for Extreme Compression of LSTM Models
Add to list
#Computer Science
#Artificial Intelligence
#Neural Networks
#Recurrent Neural Networks (RNN)
#Long short-term memory (LSTM)
#Machine Learning