#Model Optimization
YouTube
education
Showing: 145 courses

1 Lesons
1 hour 20 minutes
On-Demand
Free-Video

50 Lesons
56 minutes
On-Demand
Free-Video

1 Lesons
1 hour 31 minutes
On-Demand
Free-Video

1 Lesons
1 hour 38 minutes
On-Demand
Free-Video

1 Lesons
42 minutes
On-Demand
Free-Video

1 Lesons
31 minutes
On-Demand
Free-Video

1 Lesons
30 minutes
On-Demand
Free-Video

1 Lesons
26 minutes
On-Demand
Free-Video

1 Lesons
1 hour 28 minutes
On-Demand
Free-Video

1 Lesons
17 minutes
On-Demand
Free-Video

1 Lesons
1 hour 17 minutes
On-Demand
Free-Video

24 Lesons
3 hours 58 minutes
On-Demand
Free-Video

12 Lesons
6 hours 9 minutes
On-Demand
Free-Video

1 Lesons
40 minutes
On-Demand
Free-Video

36 Lesons
1 hour
On-Demand
Free-Video

16 Lesons
1 hour 14 minutes
On-Demand
Free-Video

24 Lesons
1 hour
On-Demand
Free-Video

16 Lesons
30 minutes
On-Demand
Free-Video

7 Lesons
26 minutes
On-Demand
Free-Video

6 Lesons
26 minutes
On-Demand
Free-Video

1 Lesons
40 minutes
On-Demand
Free-Video

51 Lesons
1 hour 24 minutes
On-Demand
Free-Video

45 Lesons
1 hour 53 minutes
On-Demand
Free-Video

58 Lesons
1 hour 43 minutes
On-Demand
Free-Video

13 Lesons
32 minutes
On-Demand
Free-Video

1 Lesons
21 minutes
On-Demand
Free-Video

1 Lesons
33 minutes
On-Demand
Free-Video

1 Lesons
22 minutes
On-Demand
Free-Video

1 Lesons
56 minutes
On-Demand
Free-Video

1 Lesons
1 hour 16 minutes
On-Demand
Free-Video

1 Lesons
1 hour 36 minutes
On-Demand
Free-Video

1 Lesons
1 hour 17 minutes
On-Demand
Free-Video

5 Lesons
13 minutes
On-Demand
Free-Video

10 Lesons
12 minutes
On-Demand
Free-Video

1 Lesons
26 minutes
On-Demand
Free-Video

8 Lesons
14 minutes
On-Demand
Free-Video

1 Lesons
12 minutes
On-Demand
Free-Video

1 Lesons
18 minutes
On-Demand
Free-Video

1 Lesons
55 minutes
On-Demand
Free-Video

1 Lesons
36 minutes
On-Demand
Free-Video

7 Lesons
28 minutes
On-Demand
Free-Video

21 Lesons
50 minutes
On-Demand
Free-Video

10 Lesons
1 hour 9 minutes
On-Demand
Free-Video

10 Lesons
30 minutes
On-Demand
Free-Video

17 Lesons
1 hour 14 minutes
On-Demand
Free-Video

25 Lesons
1 hour 15 minutes
On-Demand
Free-Video

1 Lesons
22 minutes
On-Demand
Free-Video

1 Lesons
37 minutes
On-Demand
Free-Video

17 Lesons
36 minutes
On-Demand
Free-Video

1 Lesons
27 minutes
On-Demand
Free-Video

8 Lesons
30 minutes
On-Demand
Free-Video

1 Lesons
36 minutes
On-Demand
Free-Video

1 Lesons
21 minutes
On-Demand
Free-Video
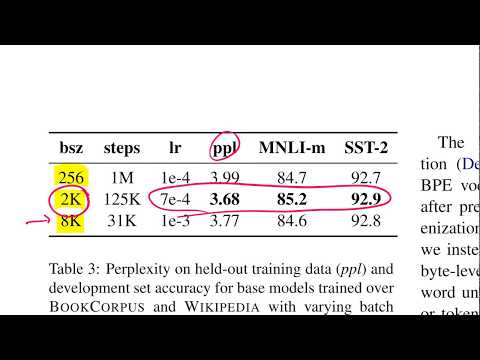
1 Lesons
19 minutes
On-Demand
Free-Video

1 Lesons
1 hour 42 minutes
On-Demand
Free-Video

10 Lesons
28 minutes
On-Demand
Free-Video

13 Lesons
26 minutes
On-Demand
Free-Video

8 Lesons
28 minutes
On-Demand
Free-Video

10 Lesons
24 minutes
On-Demand
Free-Video

30 Lesons
44 minutes
On-Demand
Free-Video

18 Lesons
35 minutes
On-Demand
Free-Video

26 Lesons
1 hour 1 minute
On-Demand
Free-Video

33 Lesons
41 minutes
On-Demand
Free-Video
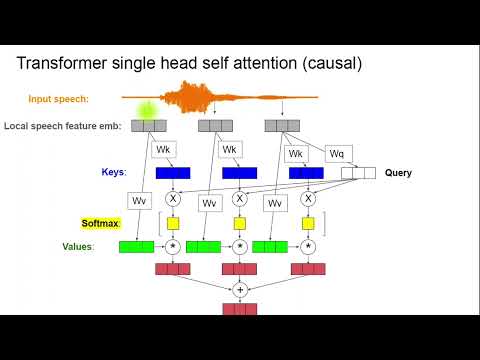
15 Lesons
26 minutes
On-Demand
Free-Video

14 Lesons
21 minutes
On-Demand
Free-Video

13 Lesons
21 minutes
On-Demand
Free-Video

11 Lesons
27 minutes
On-Demand
Free-Video

16 Lesons
1 hour
On-Demand
Free-Video

19 Lesons
36 minutes
On-Demand
Free-Video

23 Lesons
1 hour 2 minutes
On-Demand
Free-Video

10 Lesons
23 minutes
On-Demand
Free-Video

1 Lesons
31 minutes
On-Demand
Free-Video

5 Lesons
34 minutes
On-Demand
Free-Video

1 Lesons
22 minutes
On-Demand
Free-Video

21 Lesons
35 minutes
On-Demand
Free-Video

1 Lesons
53 minutes
On-Demand
Free-Video
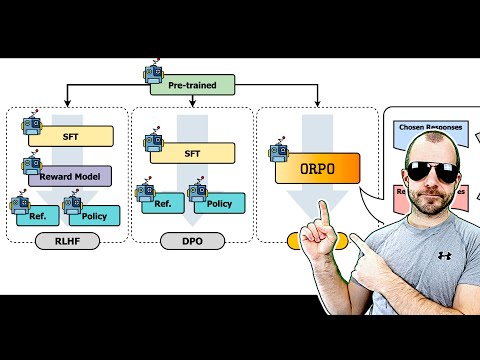
1 Lesons
33 minutes
On-Demand
Free-Video

1 Lesons
37 minutes
On-Demand
Free-Video

11 Lesons
1 hour 7 minutes
On-Demand
Free-Video

6 Lesons
26 minutes
On-Demand
Free-Video

1 Lesons
41 minutes
On-Demand
Free-Video

1 Lesons
31 minutes
On-Demand
Free-Video

14 Lesons
27 minutes
On-Demand
Free-Video

1 Lesons
30 minutes
On-Demand
Free-Video

1 Lesons
34 minutes
On-Demand
Free-Video

1 Lesons
1 hour 34 minutes
On-Demand
Free-Video

1 Lesons
1 hour 2 minutes
On-Demand
Free-Video

1 Lesons
28 minutes
On-Demand
Free-Video

1 Lesons
20 minutes
On-Demand
Free-Video

9 Lesons
23 minutes
On-Demand
Free-Video

1 Lesons
45 minutes
On-Demand
Free-Video

19 Lesons
52 minutes
On-Demand
Free-Video

1 Lesons
1 hour 5 minutes
On-Demand
Free-Video

1 Lesons
22 minutes
On-Demand
Free-Video

1 Lesons
14 minutes
On-Demand
Free-Video

1 Lesons
16 minutes
On-Demand
Free-Video

1 Lesons
22 minutes
On-Demand
Free-Video

1 Lesons
26 minutes
On-Demand
Free-Video

1 Lesons
11 minutes
On-Demand
Free-Video
