Description:
Explore a comprehensive tinyML talk on software and hardware co-design for tiny AI systems. Delve into efficient AI models through hardware-friendly model compression and topology-aware Neural Architecture Search, optimizing quality-efficiency trade-offs. Learn about cross-optimization design and efficient distributed learning for swift and scalable AI systems with specialized hardware. Discover enhancements in quality-efficiency trade-offs for alternative applications like Electronic Design Automation (EDA) and Adversarial Machine Learning. Gain insights into the future of full-stack tiny AI solutions, covering topics such as intended machines, integration, computation, accuracy engineering, neural networks, distributed learning, privacy, and edge computing. Join Yiran Chen, Chair of ACM SIGDA, as he presents a vision for the future of tiny AI systems in this hour-long exploration of cutting-edge technologies and methodologies.
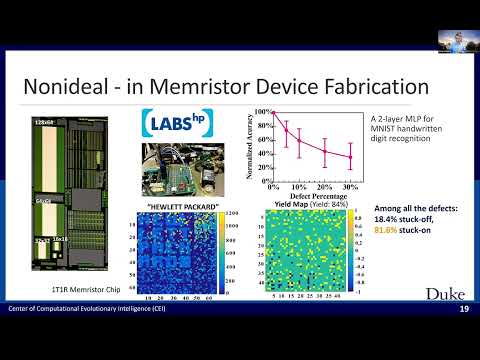
TinyML Talks - Software-Hardware Co-design for Tiny AI Systems
Add to list
#Computer Science
#Machine Learning
#Neural Architecture Search
#Model Compression
#Adversarial Machine Learning
0:00 / 0:00