Description:
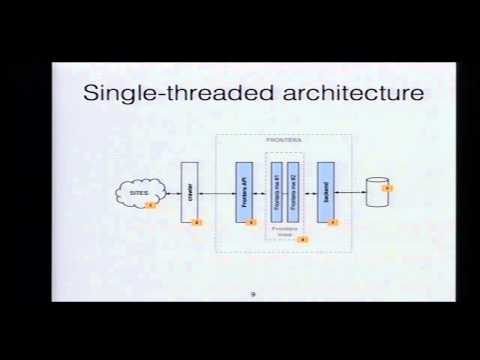
Explore the open-source Frontera framework for large-scale web crawling in this EuroPython 2015 conference talk. Discover how to build real-time distributed web crawlers and website-focused ones using Frontera's customizable URL metadata storage, crawling strategies management, and transport layer abstraction. Learn about integrating Frontera with Scrapy, Kafka, and HBase to create a powerful distributed crawler. Gain insights into the framework's architecture, features, and use cases, including a demonstration of collecting statistics from the Spanish internet. Understand the motivation behind Frontera, its single-threaded and real-time capabilities, and future development plans. Perfect for developers interested in advanced web crawling techniques and large-scale data collection.
Frontera - Open Source Large-Scale Web Crawling Framework
Add to list
#Conference Talks
#EuroPython
#Programming
#Programming Languages
#Python
#Scrapy
#Computer Science
#Distributed Systems
#Software Development
#Web Scraping
00:00
-01:18